
Patience A. Mastny and Dr. Richard W. Harris, Audiology and Speech-Language Pathology
Speech audiometry is essential to audiologists in answering questions regarding a patient’s degree of hearing loss for speech; the levels of comfortable and uncomfortable loudness; the range of comfortable loudness; and, their ability to identify accurately the sounds of speech at suprathreshold levels. Speech audiometry is also used to confirm pure tone test results, to measure the threshold for speech, and to determine amplification benefits.
Speech-reception threshold (SRT) and speech discrimination tests are important measurements in speech audiometry. Speech discrimination, defined by audiologists, is a test that demonstrates how well a person can comprehend speech at a suprathreshold level. Whereas, speech-reception threshold is the lowest hearing level at which 50% of the words presented can be identified correctly (Martin, 2000). Because it is desirable to have valid and reliable speech discrimination and SRT scores, many researchers have worked to develop standardized word lists based on word familiarity, word length, phonetic balance, talker dialect, and mode of presentation. However, not all languages have developed adequate, standardized materials for speech audiometry. Therefore, many countries are unable to perform efficiently the necessary speech audiometry tests. The purpose of my research was to develop and digitally record word lists in the Japanese language for measurement of the SRT and speech discrimination ability in patients whose native language is Japanese.
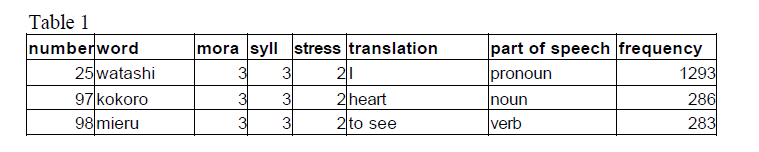
My objectives, in achieving a final digitally recorded SRT and speech discrimination test, included compiling a wordlist of the 2,000 most frequently used words in Japan. Unfortunately, there was not a computerized database with these words, their definitions in English, part of speech, syllable number, and/or stress listed and itemized according to the frequency of usage. Moreover, the frequency usage dictionaries that are printed in most other languages were unavailable to me in Japanese. Therefore, it was my responsibility to create such a list. I used a corpus of words collected from a number of 20th century novels and stories. The word frequencies had been derived at Tokyo International University. Then, I used Japanese/English dictionaries to compare kanji, mora, syllable number, stress, English definitions, and part of speech. These words were put into a spreadsheet in Microsoft Excel (Table 1).
I organized the word list based on the syllabic structure and stress patterns of the words. I discovered that contrary to the English language, there are very few spondaic words in Japan. Furthermore, the number of monosyllabic words is very small compared to English. This is important in determining what kind of word lists we will create for the final recording.
I identified a native male and a native female Japanese talker of the general dialect of Japan to serve as talkers for the recordings. These talkers were selected through a try-out process in which I recorded them reading sentences and a list of vocabulary words. Their voices were judged for: pronunciation, fluency, listening ease, and overall vocal quality by nine other native Japanese speakers.
Currently, I am working with the pre-selected talkers to record the word lists. We are using Brigham Young University’s anechoic chamber for an echo-less recording setting. The talkers are digitally recorded as they repeat each of the words on the word lists five times—such repetition ensures quality pronunciation and recording.
After the recording is finished, a native Japanese judge will rate each word for perceived quality of production. Each word to be included on the CD will then be edited to yield the same intensity as the 1000Hz calibration tone contained on the CD (ANSI 3.6-1996)
During the preliminary SRT and speech discrimination testing that will be performed after the rating process, custom software will be used to control timing and randomization of the presented words from our created lists. All testing will be done in a sound room that meets ANSI (1991) standards for maximum permissible ambient noise levels for the ears not covered condition. Each of the word lists will be presented in its entirety and then analyzed to create homogenous subsets of Japanese words that will be used in standard speech discrimination and SRT testing in Japan. Logistic regression will be used to determine the performance intensity function for each of the SRT words and for each of the speech discrimination lists.
There is a need for research within the discipline of Japanese speech audiometry to establish essential diagnosis and rehabilitation plans for the hearing impaired. High quality recordings of Japanese speech materials, review of presently practiced speech audiometry methods, and further development of improved speech-audiometry methods will make a marked difference in Japanese speech-audiometry.
Works consulted
- Martin, F. and Clark, J. (2000). Introduction to Audiology. (7th ed.). Needham Heights, MA: Allyn & Bacon.
- Nielson, W. (2000). Performance Intensity Functions for Digitally Recorded Polish Speech Audiometry Materials. Unpublished thesis, Brigham Young University, Utah.
- Nakao, S. (1997). Japanese-English English Japanese Dictionary. New York, NY: Random House, Inc.