
Jared Holcomb and Dr. Scott Woodfield, Computer Science
The hyperweb is a network based on a modified hypercube1 topology. It is used to create a peerto- peer network for a distributed database (such as a genealogical database.) Two major drawbacks that a peer-to-peer network suffers are a low reliability rate for individual nodes and a slower search speed as the system grows. Both of these problems can be addressed by replicating data across several nodes. First, any particular node has a relatively high probability of being down so a copy of the information a node contains is stored on several other nodes, thereby decreasing the total probability of information being unavailable. Second, when performing a search, a node can query the closest node in the hyperweb, thereby avoiding the extra time required to travel further across the hyperweb. The most difficult problem associated with adding replicating nodes is deciding where they should be placed so that the maximum increase in speed is achieved at the lowest cost.
A search is preformed by the cooperation of three nodes: the querying node, the indexing node, and the data node. All nodes in the hyperweb perform all three of these roles at different times. The querying node is the node where a search is originating. The indexing node is the node that contains the address of the data node. The indexing node is necessary because its address is deterministically calculated from the query string, usually by some sort of hash function. The data node actually contains the data that the querying node is requesting. To perform a search, the querying node takes a hash of the query string to get the address of the indexing node. The querying node sends the indexing node the query string. The indexing node then returns the address of the data node. The querying node finally requests the actual information from the data node, and the search is complete. To allow for a faster search and to increase the reliability of searches, the indexing information will be replicated on more than one node. All the nodes with the same indexing information are called replicas.
Three different approaches were tried to decide a method for choosing the addresses of replicas. The first method was to randomly choose a set of addresses. The second was to calculate a set of equidistant addresses. The third was to choose a regular pattern that approximated the equidistant addresses but could be calculated in much less time. The first replica in the pattern based method is placed at address 0 (addresses are expressed in binary). The second is placed at the address of all ones. The third and fourth replicas are placed at addresses with alternating ones and zeros; one starting with a one and the other starting with a zero. These three approaches were chosen because they were shown to perform well in initial tests.
The two criteria for choosing which method performed best are the average number of intermediate nodes that needed to be transversed in a search, and the amount of data that needed to be moved when the hyperweb changed in size. The first criterion relates directly with the speed of the average search and is the average distance of an arbitrary node to the nearest replica. The second criterion is important because a hyperweb will double in size each time it grows and some of the replicated data will need to be moved to the new half of the hyperweb. The best case is exactly half of the data will move to the new half and the other half will remain exactly where it is. The worst case is that all of the data will need to move to a new node on the hyperweb. These transfers must be limited as much as possible because they can represent a large use of bandwidth.
The three methods were easiest to compare using the first criterion, with no replicas as a baseline. This paper focuses on having a set of four replicas. As can be seen in the graph, a search becomes less and less efficient as the size of the hyperweb increases. Adding replicas allowed a search to take about 30% fewer hops that will equate to roughly a 30% increase in search speed. Using the equidistant method provided the best increase, followed closely by the pattern based method; random placed last.
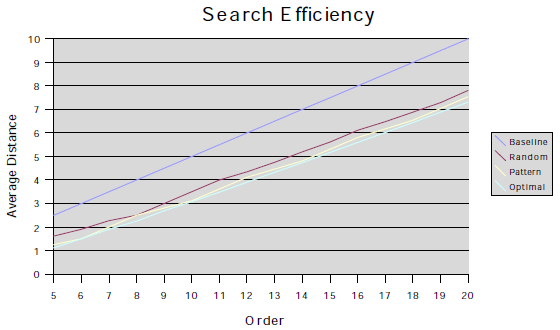
The second criterion was more subjective. Both the random and pattern based methods did well because they move on average one half of the replicas when the hyperweb changes size. The optimal does not perform as well because it will move a majority of the replicas when the hyperweb changes size. The more replicas that are moved, the more bandwidth the hyperweb requires when changing size. The random and pattern based methods preform much better because they both rely upon an absolute address that remains constant regardless of the order of the hyperweb. Replicas in the optimal based method do not have an absolute address, so they will rarely be in the same place after the hyperweb changes in size.
Overall, the pattern based method is the best choice for deciding the positions of replicas. It provides nearly as large an increase in speed as the equidistant method, and does not use as much bandwidth when changing order. The main disadvantage to the pattern based approach is that it only really makes sense when the number of replicas is a power of two.