
Todd C. Groesbeck and Dr. Scott Thomson, Mechanical Engineering
Introduction
The influence and treatment of human vocal fold scarring is a topic of great interest to the speech community (clinicians, surgeons, educators, etc). Understanding how voice production occurs “is sought in order to improve predictive, diagnostic, and corrective practices related to vocal fold health” . When a patient undergoes vocal fold surgery, scarring frequently occurs. The same surgery intended to heal the vocal fold thus leaves it damaged; scarring results in impaired vibration and prevents the individual from normal, healthy voice use.
Synthetic vocal fold models are useful in many ways. Previously, those who have studied scarring have used animal larynges. While these models may represent human vocal folds effectively for a short period of time, they are short-lived (on the order of one hour) and are difficult both to acquire and study. Synthetic models with much longer vibration lifetimes are therefore often used; however, up to this point no physical models have been developed that include the effects of scarring, which is an anticipated outcome for further research. For this project, we developed a method for fabricating multi-layer, synthetic models and compared their physical parameters such as onset pressure, subglottal pressure, and frequency with recorded human values. Results indicate that these characteristics of the synthetic models similar to human vocal folds but can still be improved.
Methodology
The first step in producing the synthetic model was creating a reverse-mold of the vocal folds. To accomplish this we used a computer-controlled wire EDM machine to manufacture an aluminum model with similar geometry to that of the human vocal folds. This model was then used to create a plastic mold. The synthetic model was then made by pouring uncured silicone into this mold. The cured silicone model was both durable and flexible.
It was desired to create several layers of different stiffness within the synthetic model to represent the human vocal fold morphology. To accomplish this, the wire EDM was used to create corresponding aluminum pieces that represented the contour of various vocal fold layers. These offset pieces were used to create a representation of three vocal fold layers: epithelium, intermediate layer, and body (see figures 1 and 2). The three layers were cast in stages using silicone materials with different stiffness characteristics.
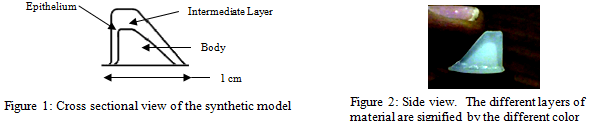
The greatest difficulty was creating the epithelial layer, which is an extremely thin, continuous surface layer (on the order of 50 microns thick in the human vocal folds). This was finally achieved by creating an aluminum piece with an offset of .004” (about 101 microns) from the surface of the original, and using that piece to create a thin, continuous layer of silicone in between this aluminum piece and the reverse mold.
Results and Conclusion
Two structurally different physical models were made and then compared to human vocal fold vibration. The first was made with only two layers, while the second had all three layers for a more correct physiological composition.
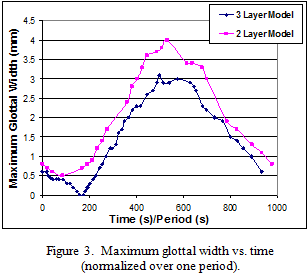
The onset pressure, or the pressure required to initiate vibration, was significantly greater for both models (9 and 7.8 kPa for the two- and three-layer models, respectively) than for the human vocal folds (approximately 0.4 kPa). This is likely due to differences in layer geometry, greater stiffness, and possible acoustic interactions with the artificial subglottal test section. Figure 3 displays maximum glottal width, both models over one period. The data suggests the models have greater stiffness than human vocal folds. Values of 3.1 and 4 mm for the two- and three- layer models, respectively, were
in the range of human vocal folds, but these values were achieved with an operating pressure of 9.9 kPa. This is on the order of 4 to 6 times that of human vocal folds (1.47 to 2.45 kPa).
The natural frequency of vibration for the two-layer model was 198 Hz, and 261 Hz for the three-layer model. These frequencies are both within the range of most human males and many human females.
In summary, significant progress has been achieved to develop a multi-layer model of the vocal folds. The model behavior demonstrated some similarities with human vocal fold behavior. Current efforts are focused on applying the model for use in voice research by developing a method for including a scar on the vocal fold. Efforts are also underway to develop more quantitative comparisons between the model and the human vocal folds, and present these results in a conference venue and in journal publication.
Reference
- Thomson, S. L., Mongeau, L., Frankel, S. H., Neubauer, J., and Berry, D. A. (2004). “Self-Oscillating
Laryngeal Models for Vocal Fold Research,” Proceedings of the 8th International Conference on Flow-Induced Vibrations, Ecole Polytechnique, Paris, France, 5 – 9 Jul 2004; Vol. 2, pp. 137-142.