Daniel J Andelin and Dr. Scott Thomson, Mechanical Engineering
Effective communication, vital to successful operations in many sectors, including military, business, and industry, depends largely on the receiver’s ability to accurately interpret the transmitted signal, generally referred to as speech intelligibility (SI). The presence of elevated noise can be seriously detrimental to SI. To reduce ambient noise in communication through audio microphones, it is possible to use a throat microphone (TM), which senses vocal fold vibrations through the skin on the speaker’s neck, as opposed to detecting the airborne sound wave emanating from the speaker’s mouth, as in standard microphones . Unfortunately, the position of the TM on the neck places it low on the vocal tract, far from the source of unvoiced sounds (such as the letters s and f). The result is an overrepresentation of voiced sounds (such as vowels), which leads to an unclear, muffled sound similar to the effect of speaking with the ears plugged.
Improvement of TM sound quality may be obtained by modifying the hardware, or possibly by using signal processing methods to modify the signal of currently existing TM models. Our goal was to explore the possibility of applying an adaptable filter to the TM signal, boosting and suppressing different frequencies by varying amounts, which would in turn alter the frequency content of the TM signal to more closely approximate the frequency content of a reference signal recorded under good conditions.
We conducted our analysis using a recording of the spoken sentence “The birch canoe slid on the smooth planks.” This sentence was recorded into two separate channels, using a throat microphone and a standard acoustic microphone (SM) simultaneously. We subsequently imported both signals into Matlab (spreadsheet software created by MathWorks) for analysis.
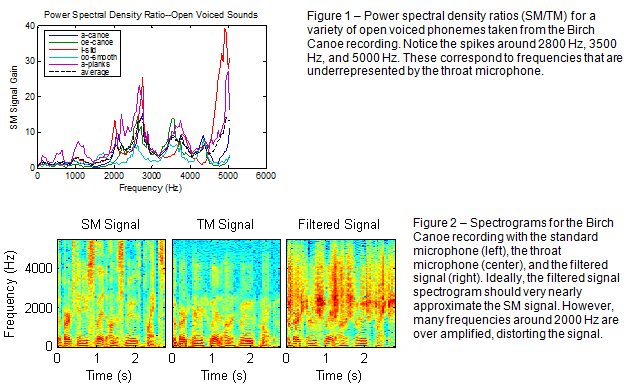
To determine the frequency response of the filter (i.e. how much of which frequencies to boost or suppress) it was first necessary to investigate patterns in frequency content of various sound types or phonemes. We grouped the various phonemes into three general sound types: open voiced (such as the vowels), closed voiced (such as the nasals m and n), and unvoiced (such as the consonant s). Using a survey of eleven phonemes taken from the Birch Canoe recordings, we examined the difference in frequency content between the TM and SM signals for each signal and compared frequency content among phonemes of the same general type (Fig. 1). We then used these power spectral density (PSD) ratio curves to define static filters for each of the three general sound types, using the average PSD ratio as our desired frequency response.
Because spoken communication consists of a combination of phonemes, a practical filter must be time adaptive, altering its frequency response based on the particular phoneme being momentarily spoken. As voiced sounds are generally characterized by lower frequency vibrations, the relative level of low frequency sound energy may be used as a criterion to distinguish between sound types. Total sound energy is related to the area under the PSD curve. To determine the level of low frequency sound energy for a given phoneme, we integrated over that phoneme’s normalized PSD curve. We found a significant difference in low frequency sound energy between voiced and unvoiced sounds (within the confines of our limited sample size). However, low frequency sound energy does not appear to be a valid criterion to distinguish between open and closed voiced sounds.
The filter we finally created resulted at best in modest improvements in the TM signal quality. Certain higher frequencies lost in TM transmission are amplified, reducing the muffled sound that accompanies the TM signal. However, many frequencies, especially around 2 kHz are over-amplified, distorting the sound (Fig. 2). In this way, the filter may actually do more harm than good.
The concept of building an adaptive filter based on phoneme type seems to be supported by our results. Patterns in PSD ratios and a physical distinction between voiced and unvoiced phonemes were shown to exist. However, empirical results show that, despite improvements in the muffled nature of the TM signal, our filter does little to increase speech intelligibility.
The results of this study can be found in the Department of Physics and Astronomy library at Brigham Young University.