
Kenneth Martin Tubbs Jr. and Dr. David W. Embley, Computer Science
Introduction
A wealth of information is locked up in millions of microfilm documents. The process of extracting and organizing this enormous amount of data is overwhelming. Automated data extraction techniques offer the ability to rapidly and systematically capture this information so that it can be stored and queried in databases. The complete process consists of these steps: convert the hand-written text to ASCII, record the text’s location, classify the text, create records from the classified text, store the records. My research focused on developing data extraction techniques for automating the recognition and creation of genealogical records from the extracted text.
My technique accepts the ASCII text of a digitized microfilm frame and produces tables of relational records as output. The extraction process uses an ontology that describes the desired genealogical records. The characteristics of this ontology are applied within search constraints to identify the records in any structured, genealogical document. These records are then automatically extracted and presented in relational tables that can be placed in a database.
Method
The process for identifying records includes four steps: apply the ontology to create a record template, adjust the record template according to the geometric relationships in the genealogical text, identify the factored data fields, and verify the extraction process. The genealogical ontology describes the semantic relationships between the classified data fields. The record formation algorithm aggregates key data fields with data fields that comply with the ontology. The algorithm prefers data fields that have a smaller “form-directed” Euclidean distance from the key data field. The record template is verified and adjusted according to the tabular geometry of the microfilm frame. This template is applied to identify all the records of its type. These steps are repeated to identify and extract multiple record types. The records can be varied and adjusted by a human user. Generated templates can then be used to exact records from the additional frames of the microfilm.
Template Creation
The goal of template creation is to define the relative positions of each of the data field types in a record. The genealogical ontology describes the possible data fields for each record. The algorithm creates a record template by identifying the types of data fields within the genealogical text and recording their relative positions. The recorded positions are relative to the position of the key data field type for the record. A key data field types can be any of the records data field types.
The algorithm looks at each of the data fields of the key type. From each key data field, it records the positions of the nearest (Euclidean distance) data fields with types that correspond to the record. The goal is to identify the relative position of the data field type with the shortest distance for the key data field type.
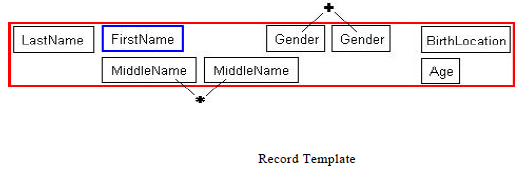
Optimal templates contain all of the data field types in the record and their positions relative to the key data field type. In the representation below the key data fields is “FirstName”. The positions of the other data field types, such as “Gender”, are recorded in relationship to their Euclidean distance to this key data field. The “*” indicates that the data field should occur zero or more time in the positions indicated. The “+” indicates that the data field should occur once and in only one of the positions indicated. The process is repeated until a template has been created for each of the records types in the text.
Record Extraction
The algorithm extracts records using the templates. The template is placed over each of the data fields of the key type. The extracted record consists of the values of the key data field and all of the data fields that correspond to the template locations.
Future Work
This geometric technique is only one approach for identifying the records given the ASCII data of a microfilm record. In addition to this technique, I will use other methods to identify records. Each method will provide a confidence level for its results. The results of the individual measures will then be compared in order to identify the records.