
James Longstaff and Deryle Lonsdale, Linguistics
Introduction and Purpose
The purpose of this project is to improve Arabic automatic speech recognition (ASR) by distinguishing
between different dialects with the use of machine learning.
Machine learning is the teaching of computers to recognize and distinguish between categories by
themselves. Machine learning works off of statistical and mathematical algorithms implemented with
computer programming.
According to the literature, the majority of the approaches to this problem took into account only
phonetics to distinguish between different dialects (F.S. Alfori, 2008) (Biadsy, 2016) (Thompson, 1996).
Unlike other ASR programs, this approach took into account the linguistic characteristic of usage.
Since a specific word can appear in two dialects either in frequency or in different frequencies, the goal
of this project is to take into account this covariation to classify between two dialects. The idea is that a
certain word may appear in only one dialect, but not another or that a certain word may appear in both
dialects, but people in one dialect use the word more often than people in another dialect. This project
attempts to use these subtle variations to classify usage.
Data
The data consists of around 200 hours of Arabic telephone conversations in two Arabic dialects: ‘Gulf’
and and ‘Levantine’ (LDC, 2002, 2006, 2005). The data was collected with the consent of those involved
in the study. The Arabic speakers that participated in the study knew their phone conversations were
being recorded and they were compensated for the recordings. This dataset is from the Language Data
Consortium (). I initially thought that I had reliable Egyptian data, bit upon further inspection, I did not.
The telephone conversations from the ‘Gulf’ dialect contain conversations of Arabic speakers from
Oman, Saudi Arabia, Bahrain, Kuwait, the U.A.E., and Qatar.
The telephone conversations from ‘Levantine’ dialect contain conversations of Arabic speakers from
Lebanon, Syria, Jordan, and Palestine.
It was initially thought that the dataset contained neat time-aligned data. However, this was not the case.
This means that although the dataset had the recordings of the conversations, it was not neatly divided
by word so that I could analyze the phonemes. This made the process impossible to analyze the
phonetics.
Despite this deficiency in the data, the data did contain transcriptions of each of the conversations.
These texts files with the transcriptions of the data made it possible for me to move forward with the
distinguishing the dialects based on usage. The text files of the conversations became the data used in
this study.
Data Organizing and Cleaning
With the help of regular expressions and other computer programming tools, it was possible to count
how often a word came up in conversation. By counting the words, it was then possible to make a list of
how much a word shows up in each dialect.
In this project we compile two separate lists of words. Using these lists of words we will develop a
feature vector with which machine learning algorithms will analyze. Another perspective on feature
vectors is that it is the step where a statistical model is created. In this project, the model is created and
then tested. Anyone with experience in statistics and science understand that developing a statistical
model is an art.
After tallying up a list of the words that were used the most, I created two lists two take into account
uniqueness and frequency aspect of usage. One of the lists is a unique words list and the other list is a
common words list. Unique words are words used in one dialect, but is not used in any other dialect. Most
Common words (or common words) are words that are commonly used in this dialect, whether they are
found in any other dialect or not.
Each time-aligned text file represents a single conversation. Each of the speakers speak the same dialect.
Since transcriptions of people’s conversations are not neat data frames, one of the challenges of this
project is to convert raw text files into data frames. The scope of the project did not allow us the time to
examine the audio files.
Here are the steps that are taken to convert the data from a transcribed text file into a feature vector:
1) Divide the sentences of person A and person B.
2) Remove all non-Arabic characters from the conversation.
3) Organize each line into a row of a matrix where each columns is one Arabic word right after another.
4) Use this matrix top count the number of times a word in our feature vector is used. Depending on how
many times a feature vector word is used, increases the value of the word within the conversation.
5) From here we calculate a percentage for each word in our feature vector depending on how many times
it is used.
Working with Arabic Characters
Arabic characters are not found in the standard ASCII library. Because of this difference, we use unicode
characters to represent Arabic script.
Data Visualizations
Three data visualizations are featured below. The visualizations below assist in understanding how two
words in our feature vector covary. The data visualizations below corresponds to the frequency of the
words used within a conversation, not the percentage frequencies of the data. Although there are many
more possible visualizations, the three below represent the utility of the data visualizations in the
classification effort.
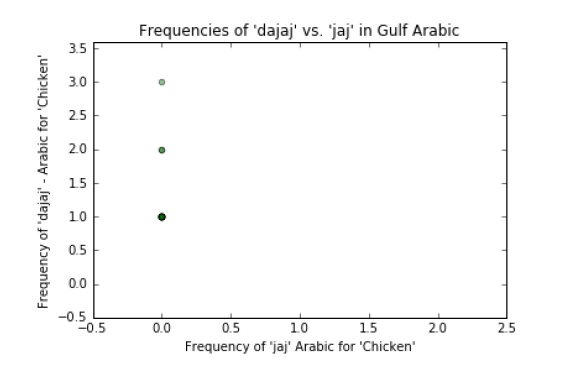
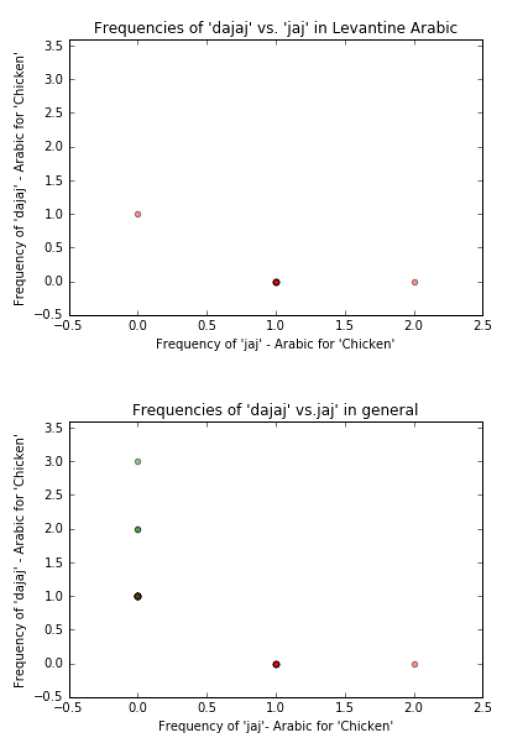
Graph جاج’ : 1 ‘ vs. ‘ دجاج ‘ (jaj vs. dajaj). Both of these words mean ‘chicken’, however ‘ جاج ‘ is more
Levantine while ‘ دجاج ‘ is common across more dialects. Both of these words are not mentioned a lot in
either dialect. If we can train our algorithm on subtle word choices like this, then it can add a more robust
analysis of our algorithm. Our hypothesis is that ‘ جاج ‘ is used more in Levantine and ‘ دجاج ‘ is used more in
Gulf Arabic.
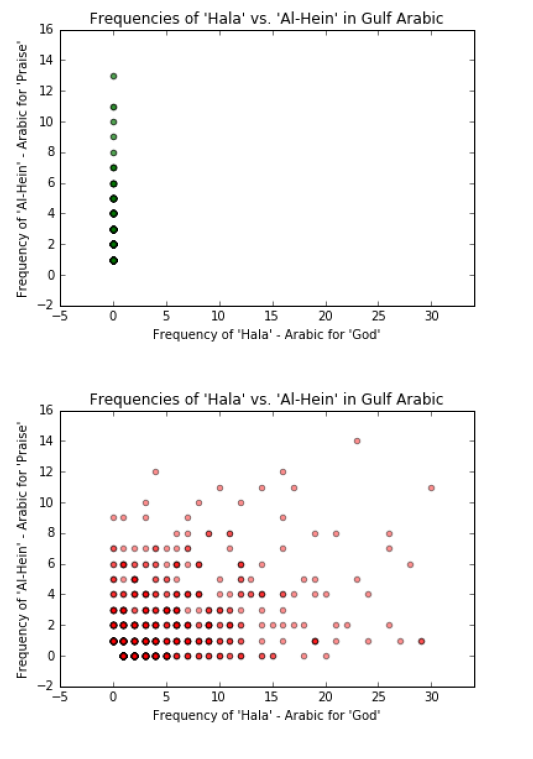
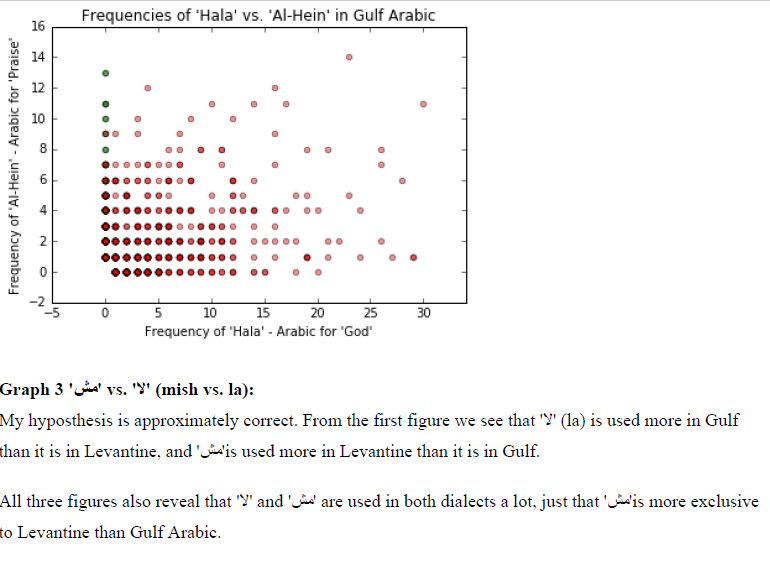
Graph حالا’ : 2 ‘ vs.’ الحین ‘ (Hala vs. Al-Hain). Both of these words mean ‘now’, however, ‘ الحین ‘ is known to
be from the gulf dialect and ‘ حالا ‘ is known to be more Levantine.
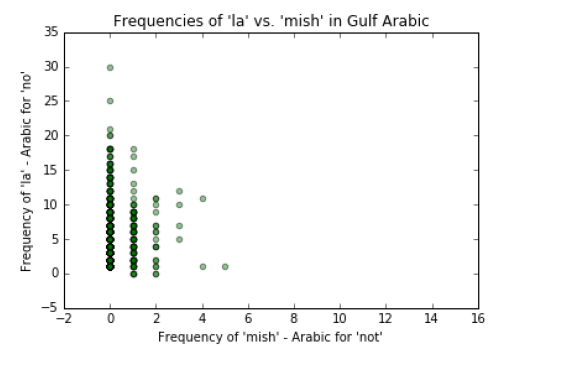
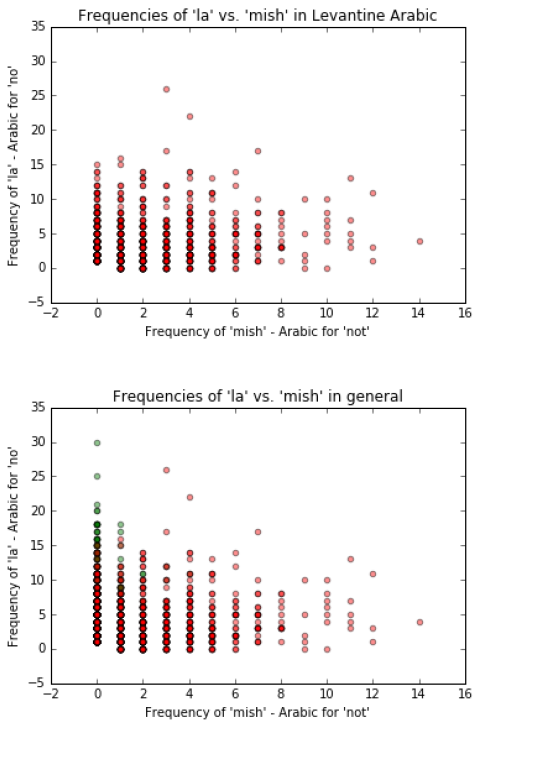
Graph مش’ : 3 ‘ vs. ‘ لا’ (mish vs. la). These words are negation particles. Our hypothesis is that ‘ مش ‘ (mish) is
used in Levantine more than it is used in Gulf Arabic and ‘ لا’ is used more in Gulf Arabic than it is in
Levantine.
Graph جاج’ 1 ‘ vs. ‘ دجاج ‘ (jaj vs. dajaj):
Although the points on these there graphs are sparse, the visualizations are still very helpful.
You can clearly see a distinction between the two dialects as was predicted in our hypothesis above.
For clarification sake, our hypothesis was that ‘jaj’ is spoken in Levantine Arabic while ‘dajaj’ is spoken in
Gulf Arabic.
In all instances if one ‘jaj’ is used in the conversations, then ‘dajaj’ is not used in that same conversation
and vice versa. This indicates a consistency for the speaker in either always saying ‘jaj’ or always saying
‘dajaj’.
Although there is one Levantine speaker that says ‘dajaj’, for the most part all three of these figures
indicated that Levantine speakers tend to say ‘jaj’ while Gulf speakers say ‘dajaj’.
Since ‘jaj’ is never used in Gulf Arabic, we can conclucde that the use of ‘jaj’ implies the speaker is
Levantine.
My hyposthesis is approximately correct. From the first figure we see that ‘ لا’ (la) is used more in Gulf
than it is in Levantine, and ‘ مش ‘is used more in Levantine than it is in Gulf.
All three figures also reveal that ‘ لا’ and ‘ مش ‘ are used in both dialects a lot, just that ‘ مش ‘is more exclusive
to Levantine than Gulf Arabic.
Graph حالا’ 2 ‘ vs.’ الحین ‘ (Hala vs. Al-Hain):
Al Hein is known to be uniquely Gulf and Hala is known to be more Levantine than Gulf. Our dataset and
this visualization reflects this attribute of the language.
Feature Engineering
Feature engineering is the choosing of variables to consider in your statistical model. Before choosing
what features to include and what features to ignore, a list of the most common words and unique words.
The details of this are discussed in the “Data Organizing and Cleaning” section above.
By taking 40 unique words from the unique words list and the most common words of each dialect and a
few other words based on personal experience with Arabic, we end up with a feature vector with 74
unique features. Each of these features represents a word. Some words are found in both the unique
words, and common words lists.
Once the words from each conversation are counted and scaled, we end up with the feature vector.
In addition to using these two lists, a few unique words were added based on personal conversation with
native Arabic speakers. After receiving a recommendation from these native Arabic speakers and before
adding these words to the feature vector, the data visualizations were consulted to see if these words were
matches for the model.
This decision to ask native Arabic speakers about unique words in their dialect or another dialect, may
seem unscientific, however, by consulting the data visualizations, it turns out that this modeling decision
is backed by data.
Analysis/Machine Learning Algorithms
After carefully creating the feature vector with 74 different variables, 10 different machine learning
algorithms are used to analyze the feature vector. The algorithms which were tested were: trees, random
forests, an XG boosting algorithm, gradient boosting algorithms, K-nearest neighbors algorithms, Radius
Nearest Neighbors, Naive Bayes, Linear Discriminant Analysis, Quadratic Discriminant Analysis, and
Support Vector Machine. The variables for the Gradient boosting algorithms, random forests, and XG
boosting algorithms in the python scikit learn package were toggled and modified with and then the
misclassification value was averaged. The misclassification error results never varied more than 0.001 or
0.1%.
Below is a list of the algorithms and their misclassification error. For example if the misclassification
error is 0.022, then that means the algorithm misclassified the data 2.2% of the time. The higher the
misclassification error, the least accurate the result.
Conclusion
In conclusion, the model created in this project is suitable method to take into account the linguistic
characteristic of usage. As evidenced by the machine learning algorithms, for the majority of the
algorithms that were considered, there is very high amount of evidence to suggest that this model was
successful. Although the SVM Sigmoid, SVM Polynomial, SVM RBF, and Radius Nearest Neighbors,
had very unsuccessful results, because the strengths and weaknesses of different machine learning
algorithms sometimes one algorithm is good for you data while another is not.
As shown by the Data Visualizations, the data for this project is more suited for clustering algorithms like
K-Nearest Neighbors, Random Forests, and Trees.
The SVM algorithms were expected to be less successful because they work by distinguishing a line,
polynomial, or sigmoid and then determining if it is on one side of the sigmoid or not. This does not work
with the data/feature vectors in this project because that would assume that both dialects never share
words.
Since the Levantine dialect and the Gulf dialects do share words, the SVM approach fails. However, the
clustering algorithms are more suited to take into account the variations in graph 2 and graph 3.
This project was a first attempt to consider the dimension usage in an Automatic Speech Recognition
Algorithm. As this project ignores speech recognition due to the limitations of the data, future research
still needs to take this project in usage and bridge it with what has been done in ASR with phonetics. In
addition to combining ASR with the work in this project, there needs to be more research done
developing methods in classifying usage.
Bibliography:
F.S. Alfori. 2008. PhD Dissertation: Automatic Identification Of Arabic Dialects Using Hidden Markov
Models. In University of Pittsburgh.
Biadsy, Fadi, Julia Hirschberg, and Nizar Habash. “Spoken Arabic Dialect Identification Using
Phonotactic Modeling.” EACL 2009 Workshop on Computational Approaches to Semitic Languages
(2009): 53-61. Web. 12 Oct. 2016.
Thompson, Steven K., and G. A. F. Seber. Adaptive Sampling. New York: Wiley, 1996. Print.
Maamouri, Mohamed, and Hubert Jin. Arabic CTS Levantine Fisher Training Data Set 3, Speech
LDC2005S07. DVD. Philadelphia: Linguistic Data Consortium, 2005.