
Faculty Mentor: Deryle Lonsdale, Linguistics Department
Abstract
This study uses an open source statistical machine translation system (Moses) to
perform machine translation for specific domains, or text types. A machine translation
system can be adapted to a specific domain by using training data from the same
domain. In this work we show significant improvements for machine translation by
training for specific domains and compare the effectiveness of using training data in
each of these domains. We also evaluate the effectiveness of different amounts of
training data and combining data from different domains.
Introduction
Adapting machine translation to specific domains or subject matter is essential to
improve translation quality, and this is still a new field of research. Professional
translators need to translate documents with the subject matter and domain in mind, in
order to create a translation that uses the correct type of language and terminology for
the domain, whether it be legal, political, technological, religious, or other types of
documents. A statistical machine translation system trained on text of a particular
domain is expected to perform better on other text of this same domain.1 In this work we
experiment translating from Spanish to English with the following domains: legal,
political, financial, and technological.
Truecasing
Truecasing corrects casing at the beginning of sentences.
Before truecasing: i’m a cat.
After truecasing: I’m a cat.
Cleaning
Cleaning removes blank lines, sentences with over 80 characters, and mis-aligned
sentences.
To create the training and test sets, lines are randomly picked for each set among the
corpora. 10,000 lines are reserved and used for testing, except in the case of the
Gnome translation model testing on Gnome text, where 1,000 lines are used for testing
(because only 13,965 of Gnome lines are available in total).
The Wikipedia corpus is used as generic data and as a baseline because it consists of a
large variety of topics, and it is also a relatively large corpus (1,811,428 total).
The training data consists of parallel bilingual files. Our training data comes from the
OPUS3 website. We used the following domains and corpora in our research:
Generic
Wikipedia: Various topics.
Legal
DGT (Directorate-General for Translation): Translation memories for legal
translations.
EU (European Union) Bookshop: Legal book translations.
Financial
ECB: Website and documentation from European Central Bank.
Technological
KDE4: Software localization files.
Gnome: Software localization files.
The translation model was created using GIZA++4, and is a phrase table with Spanish
sentences aligned with English sentences, with the likelihood of the translation (based
on the frequency of occurrence in the training data).
An n-gram language model (where n = 3) was used to output a translation in English
that is most likely based on frequencies of words, bigrams, and trigrams in the training
data. We created the language models using KenLM5. For all experiments in this
project, the same data or corpora used for the translation model was used for the language model, and we sometimes refer to both a translation model and a language model as simply “translation model,” or the translation system trained by Moses.
We used Python scripts to run the commands to prepare, separate (creating test and
training sets), train, and test the data sets for the experiments. These scripts are
available at the following link: https://github.com/JoshuaMathias/moses-scripts
Each experiment or model required around 15-20 minutes to train and 15-20 minutes to
test on a laptop with a 2.8 GHz Intel processor.
The translation quality is evaluated using the BLEU6 score, which is the standard for
automatically evaluating translation quality, by comparing the translation output with a
reference human translation.
Results
Each model is tested on each test set (and therefore each domain). The BLEU scores
of these tests are shown in the following table and graph (Figures 1 and 2).
Figure
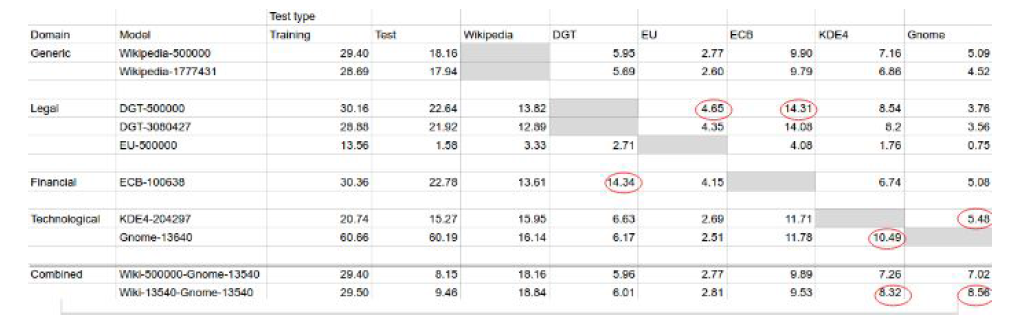
The highest BLEU score for the ECB (financial) test was performed by the DGT model.
This may be because the bank documents of ECB are similar to the legal documents of
the DGT corpus.
Similar results were found for the KDE4 and Gnome tests. The highest BLEU score on
KDE4 text was 10.49, by the Gnome model, and was 1.95 points higher than the
second best score. The highest score on the Gnome text was 5.48, by the KDE4 model,
.4 higher than the second best score. These results indicate that using technological
training data (or text) to perform translations on technological data is more effective than
training on data of other domains.
As listed in the table, we trained and tested two models with the DGT corpus and two
models with the Wikipedia corpus, where one was trained on 500,000 lines, and the
other on all lines available (minus the test set). The large Wikipedia model was trained
on 1,777,431 lines and the large DGT model was trained on 3,080,427 lines. For both
the Wikipedia models and the DGT models, the larger models performed consistently
worse (yet similar) to the 500,000 line models. A graph comparing the two Wikipedia
models is shown below.
These results were surprising, as one would expect a translation model and language
model trained on a larger corpus to output better translations. The effectiveness of the
smaller model is evidence that after a reasonable amount of data (500,000 lines) is
used from a particular corpus, no more data from the same corpus is needed to improve
translations, and may even worsen translations. It is likely effective, however, to add
data from other corpora.
We decided to test the hypothesis that a translation model trained on text combining the
generic Wikipedia text with text from another domain would improve results on that
domain. For this purpose we used Gnome, the smallest corpus used in our research,
and we created two translation models, one using 500,000 lines from Wikipedia with
13,540 lines from Gnome, and another using 13,540 lines from Wikipedia with 13,540
lines from Gnome (to even out likelihoods between text from Wikipedia and text from
Gnome). The results are found in Figure 1 to compare with previous tests. The following
graph compares both of these combined models with the 500,000 lines Wikipedia
model.
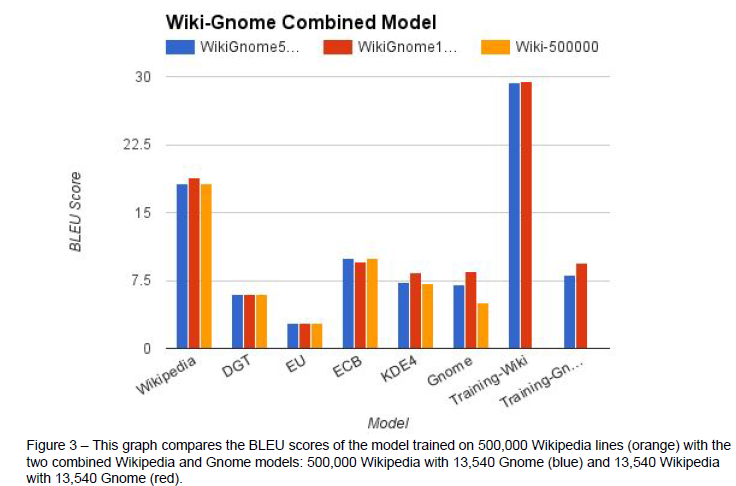
The combined model using 500,000 Wikipedia lines performed about the same or better
as both of the plain Wikipedia models, with the most improvement applying to the
Gnome test set (1.93 improvement) and secondly to the similar KDE4 test set (.1
improvement).
The combined model using only 13,540 Wikipedia lines performed better on all test sets
than the combined model using 500,000 Wikipedia lines, even showing an improvement
of .68 BLEU points on the Wikipedia test set compared to the plain 500,000 Wikipedia
model, despite using much less training data. The 13,540 Wikipedia combined model
showed an improvement of 3.47 BLEU points on the Gnome test set and 1.16 points on
the KDE4 test sets compared to the plain 500,000 Wikipedia model. Overall both
combined models performed the same or better on all test sets except for a decrease of
.37 BLEU points on the ECB test set. These results indicate the advantage of training a
translation model on different types of corpora, or different domains.
Conclusion
As expected, training a translation and language model on corpora of the same domain
as the text to be translated improves translation results. We also found that training on
large amounts of text may even worsen results compared to training on smaller
amounts of text. In addition, training on text from different domains improved results on
almost all domains. In conclusion, it is important to use text similar to the type of text to be translated when training a translation model, and combining relatively small amounts
of text (such as 13,000 lines) of different types for training data may improve translation.
Future Work
Many more domains, corpora, amounts of training data, and combinations can be tested
to evaluate the effectiveness of using different types of text to train translation and
language models. Since using training data from one domain may worsen translations
of another domain, translations may improve by using different translation models for
different types of texts. Because the type of text used for training may be more
significant than using a large amount of text (as our results show), translation results
may be improved by selectively choosing training data based on common words and
phrases of the text to be translated or the domain of the text to be translated (such as
legal, medical, technological).
References
1 Koehn, P., & Schroeder, J. (2007). Experiments in domain adaptation for statistical machine translation.
Proceedings of the Second Work shop on Statistical Machine Translation, 224-227.
2 Moses. (2016, September 8). Retrieved December 29, 2016, from http://www.statmt.org/moses/
3 OPUS … the open parallel corpus. (n.d.). Retrieved from http://opus.lingfil.uu.se
4 GIZA. (n.d.). Retrieved December 30, 2016, from http://www.statmt.org/moses/giza/GIZA++.html
5 KenLM Language Model Toolkit. (n.d.). Retrieved December 30, 2016, from
http://kheafield.com/code/kenlm/
6 Papineni, K., Roukos, S., Ward, T., & Zhu, W. J. (2002, July). BLEU: a method for automatic evaluation of
machine translation. In Proceedings of the 40th annual meeting on association for computational
linguistics (pp. 311-318). Association for Computational Linguistics.