
Emily Duncan and Ron Channell, Communication Disorders
Introduction
It was our desire to investigate further, using a computer model, how children acquire language. Specifically, we decided to investigate how children learn how to arrange grammatical tags (i.e. grammatical categories: verb, adjective, etc.) into the proper order. Originally, we were going to investigate how an evolutionary algorithm could improve the degree of accuracy in re-ordering grammatical tags. However, we decided to branch off of a previous study to gain a better understanding of the potential of a computer model to re-order the grammatical tags with just the tag transition probabilities. In her thesis last year, Katie Shaw Walker, a graduate student, used 8 child/adult samples with this question in mind. The computer model was trained with the statistical data from the adult utterances and then was tested on the child’s utterances. Each word in Katie’s study had its most likely grammatical category assigned to each word. The findings were that the model could re-order the child’s utterances with an 80-90% accuracy. For our study, each word was randomly assigned a grammatical category. This divergence was intended to give us a better understanding as to how the computer program would do with randomly assigned tags. We were surprised to find that the program could already achieve higher than chance results simply by learning from the parent’s utterances.
Methodology
All 8 samples were used twice in our study. The first time around, a set of 25 random grammatical categories were applied; the second time, a set of 100. This was done to see if there was a difference in the percent of accuracy when there were more grammatical tags available. Like Katie’s study, we used the adult utterances to train the computer and the child utterances to test the computer. First, the adult words are all tagged with a randomly assigned grammatical tag and the computer calculated the tag transition probability, which is the probability of one grammatical tag relative to the others. Then, the child words are tagged with the same tag set and the tag transition probability from the adult samples are applied to the child’s. This allowed the computer to apply what it learned from the adult’s sample to the child’s. This process was replicated 30 times with both the set of 25 and 100 grammatical tags.
Results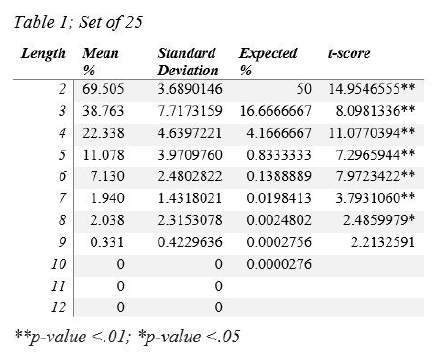
We found that even with randomly assigned tags, the results were higher than chance. It was also discovered that the percent of accuracy was higher with the set of 100 grammatical tags than the set of 25. This was unexpected because with fewer options, the set of 25 should get a higher degree of accuracy. However, we found the opposite to be true in our study. The “Expected %” column on Table 1 and Table 2 indicates the percentage that indicates chance (i.e. the percentage of accuracy when you flip a coin or roll a die). In the “t-score” column, many of the percentages are significantly higher than chance for utterances 8 words or less. Additionally, the p-values for the ttests indicate significant differences which support the hypothesis that a computer program can successfully reorder the scrambled child utterances based on the application of the tag transition probability gained from the adult utterances.
Discussion
Our study has shown that for those who choose to study models of children’s grammatical tagging, just 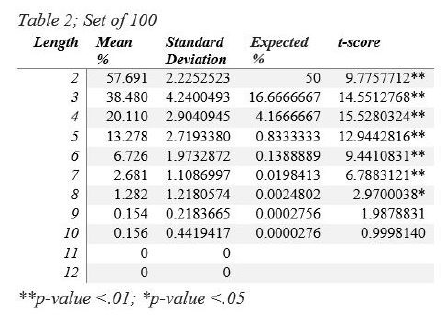 getting higher than chance re-assembly isn’t enough for a strong result. We received that result with randomly assigned grammatical tags for words. This is a small step toward understanding how children acquire language, but it is an important one for exploring how children learn language.
getting higher than chance re-assembly isn’t enough for a strong result. We received that result with randomly assigned grammatical tags for words. This is a small step toward understanding how children acquire language, but it is an important one for exploring how children learn language.
Conclusion
This study has helped us understand how the data naturally behaves without a learning algorithm, such as evolutionary programming, applied. This way, we will be better able to assess the effect of an evolutionary algorithm in future research.
References:
- Walker, Katie Lynn. (2016) “Modeling Children’s Organization of Utterances Using Statistical Information from Adult Language Input” (Unpublished master’s thesis). Brigham Young University, Provo, UT.