
Gerrit Noorda, Braden Hancock and Christopher A. Mattson, Mechanical Engineering Department
Introduction
In our proposal for an ORCA grant, we planned to use machine learning to socially benefit others with our research. In the early stages of the research, however, we came across a different, more urgent problem. We decided to use the same principles of research, but in a different way. When searching for large data sets, we discovered vast, largely unused collections of data, collected and given out by the World Bank Group. Ultimately, we decided to use the data to answer other social questions.
Methodology
The World Bank Group offers all sorts of data on many countries. There are all sorts of indicators covering a variety of areas, such as economic, trade, climate change, and education. There are hundreds of indicators given here. Some are raw data, such as population or percentage of people attending school. Others are indexes.
Our goal was to be able to recreate these indexes using the raw data. Some are easy, such as GDP per capita. It is simply the the total GDP of the country divided by the total population. Others are more difficult and it is not known exactly how the specific index number was found. Once we reverse engineered the algorithm, we could take the sets of raw data, plug them into the algorithm and end up with the index number given.
For example, the United Nations gives out an annual report called the Human Development Report. They create a number and rank each country with their Human Development Index, or HDI. To recreate this number is more complex than some others, say GDP per capita. using the data given, we were able to recreate these numbers. This algorithm is as follows:
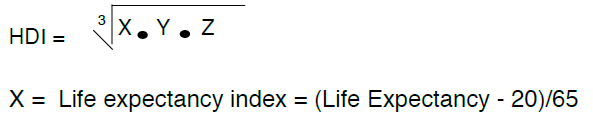

First, we took the index and found the algorithm used to create it. Once that was found, the next step was to write a code so that the computer can run the data and come up with the final numbers on a large scale. After the code is written, any numbers can be inserted as the initial data entries and the computed index will be the result. The final step is to get an easy way of reporting the computed results. That way, if someone needed the index for a specific country, you can just run the code and get the results.
Results
The results are very promising on this project. They are, however, far from finished. This project will continue into the fall and will hopefully transform into a larger scale research project. With this research, we have extended the functionality of the data. Instead of just knowing where a country ranks and their individual number in a certain index, we can now know much more about it all. We can understand what makes countries rank where they are. We can understand why a country with high levels of income is not necessarily at the top of the list for everything. We can even apply this to communities, families, or any other sort of group of people, not just to countries. As long as we can get the raw data needed on the group, we can calculate their result. This is another application of this that can be very beneficial to society and the world.
Conclusion
Thanks to the funding received as the ORCA grant, we have been able to start this research that will be hopefully be socially beneficial to many people and organizations. Our ultimate goal is to create a database, accessible to all, which will hold all this data and calculations. When completed, people and groups will be able to request a report about a specific country, multiple countries, or any sort of data we have. We will continue this project and hope it will continue to yield the same promising results we have discovered so far.