
Maria Sanchez Wals, Katherine Washburn, Nathan Glenn, and Professor Ray Graham, McKay School of Education
Main Text
According to research, a reader needs to understand at least 95% of running words in a text in order to comprehend the text and to learn new words from context (Hu & Nation, 2000; Nation 2006). In an effective language and literacy program, selecting the appropriate text and pre-teaching key vocabulary is essential; but for teachers it is a time consuming task to find leveled texts and identify the key vocabulary words in the reading.
As a response to that need, several universities and private companies have developed tools and leveled readers in English that facilitate educators to prepare their literacy instruction, including explicit vocabulary instruction. Tools such as Lextutor Vocabulary Profiler developed by the University of Montreal (Cobb, 2006) are very valuable for educators, but resources like Lextutor have not been available in Spanish. Thus, we decided to create an on-line tool that will enable educators to profile Spanish text and obtain a summary of the text characteristics so that a vocabulary lesson and appropriate pre-reading activities can be designed.
Creating this tool was a challenge; there were not any lists of words categorized by family frequency or academic usage in Spanish such as those developed by Michael West (1953), Xue & Nation (1984), or Averil Cohexad (2000) for English. There are some published dictionaries in Spanish that include some words of the same family in the word entry, or high frequency words; but none of the current publications include a systematic approach to group all the words of the same family and none of them organize their entries by their frequency of occurrence in the written corpus (Haensch, 2004).
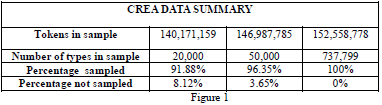
First, Dr. Ray Graham and Maria Sanchez began by analyzing the Spanish written corpus and frequency list created by the Real Academia Española de la Lengua (RAE, 2008), who has created a corpus database with over 772,000 different entries, known as the Reference Corpus of Current Spanish (Corpus de Referencia del Español Actual , CREA). This Spanish corpus and reference list was created after analyzing almost 5,500 different texts and over 152 million words gathered from diverse media and geographic origin (Spain and Latin America) from 1975 until 2004. Then, we chose the 20,000 words with highest frequencies in the corpus and identified all the words that shared the same free morpheme, or root, to establish the word families. These 20,000 words account for 92% of all the occurrences in the CREA list (figure 1). Once the word families were established, we added their individual word frequencies to obtain the absolute frequency for the free morpheme or word family and obtain a list of word families by frequency in the Spanish corpus.
Then, a development team (Maria Sanchez, Katherine Washburn and Nathan Glenn), under the direction of Dr. Ray Graham, created the application for an on-line tool that allows users to profile texts in Spanish, the Spanish Vocabulary Online Profiler (SVOP), available at http://ei.byu.edu/svop/. SVOP analyzes any given written text and categorizes each word in the text according to its frequency in the Spanish written corpus (CREA) and reports how many words the text contains from the following categories:
1. K-1: a list of the 1000 most frequent word families.
2. K-2: a list with the second most frequent 1000 words families.
3. PNA: a list of common proper nouns and adjectives of origin (e.g. Pedro, Mexico, americano).
4. AWL: the Academic Word and Vocabulary List, which is composed of the word families included in the most common 20,000 words in the Spanish corpus (except those included in other categories: K1, K2, PNA).
5. OFF List: any given word that does not appear on other lists (K1, K2, PNA, AWL).
Future research and development of this on-line tool will include the development of a high frequency academic word list (Lista Académica de Alta Frecuencia, LAAF), an online dictionary, and an expansion of the current database. The high frequency academic word list (LAAF) will include a list of the 500 most common words to all the different fields of knowledge such as science, arts, psychology, etc. The on-line dictionary will provide the user with access to our word-family database and will allow to retrieve information on the individual and family frequencies for any given word. Also, we will expand our database with 30,000 more terms grouped into families to account for 97% of the entire corpus.
References
- Cobb, T. (2006).The compleat lexical tutor for data-driven learning on the web. [Webbased suite of programs]. Montreal: University of Quebec. Available: http://lextutor.ca/
- Coxhead, A. (2000). A new academic word list. TESOL Quarterly, 34(2), 213-238.
- Hu, M., & Nation, I.S.P. (2000). Vocabulary density and reading comprehension. Reading in a Foreign Language, 13(1), 403-430.
- Haensch, G. (2004) Los Diccionarios del Español en el Siglo XXI. Universidad de Salamanca. Salamanca, Spain.
- Nation, I.S.P. (2006). How large a vocabulary is needed for reading and listening? The Canadian Modern Language Review, 63(1), 59-82.
- RAE (2008). REAL ACADEMIA ESPAÑOLA: Banco de datos (CREA) [en línea]. Corpus de referencia del español actual. <http://www.rae.es> [Oct 16, 2009].
- West, M. (1953). A General Service List of English Words, Longman, London.
Xue G.; Nation, I.S.P. (1984). A University Word List, Language Learning and Communication 3, 2:215-229.