
Ryan Jenkins and Dr. Scott Thomson, Mechanical Engineering
Introduction:
The vocal folds are two multi-layered regions of tissue located in the larynx that vibrate as air flows past from the lungs. This vibration is the basis of voiced speech, one of mankind’s primary means of expression. Due to a complex fluid-structure-acoustic interaction and the inaccessibility of in vivo tissue for observation, synthetic models have been developed and used to study different aspects of the mechanics of speech production. This project compared the performance of two self-oscillating synthetic vocal fold models that differed in their composition of an internal tissue layer called the intermediate layer of the lamina propria. Until this project, difficulties in getting consistent models have been largely due to the thinness and embedded acrylic fiber in this layer.
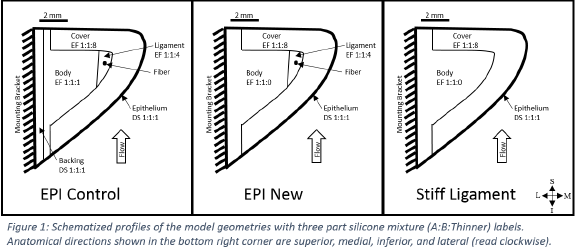
The two models studied were the four-layer “EPI Model” and a three-layer derivative—the “Stiff Ligament Model (SLM).” Figure 1 shows schematized cross sections of the model geometries. A slight modification was made to the EPI model for the purpose of simplifying comparison between the EPI and SLM models. This modification dealt with the body layer of the EPI test model, EPI New in figure 1, and traditionally made EPI models, EPI control in figure 1.
Methodology:
Models were cast from two types of silicone rubber, Ecoflex® Supersoft 0030 (EF) and Dragon Skin® 10 Fast (DS), using molds of the different geometry layers. For each model layer, a batch of silicone was prepared to cast multiple replicates. EPI New and SLM models were cast simultaneously to ensure that material properties were consistent between model types, making the proposed geometry change the only difference between models.
Each model set consisted of two folds, mounted in acrylic brackets, aligned and brought together so that the superior surfaces were flush and the medial edges touching. The sets were then attached to an air supply tube. The length of the air supply tube was varied for different tests to provide a second variable for comparison. A pressure transducer was mounted just below the model’s inferior side to monitor the onset pressure of vibration while a flow meter upstream monitored the flow rate. A high-speed camera was oriented directly above the models to record their motion. Vibration onset pressure, vibration frequency, air flow rate, and high-speed camera data were recorded for each set.
Statistical and graphical analyses were performed on the pressure, frequency, flow rate, and material property data for model comparisons. A custom MATLAB program took each high-speed camera image and measured how much each fold moved and the area between the folds. A second custom MATLAB program took the images from four different test cases, added labels, and stitched them together into a video file showing the test cases side-by-side for comparison. Both individual and group comparison videos were used to qualitatively analyze model motion in relation to endoscopic stroboscopy videos of human vocal folds in vivo.
Results:
When the results from the vibration tests were averaged across runs and model replicates, each model type showed a decrease in onset pressure and flow rate and an increase in vibration frequency with increased duct length from the baseline 17 cm duct length. These differences between duct lengths were statistically most significant for the SLM models, followed by the EPI New and EPI control models. The SLM results at both duct lengths were consistently within the range of the EPI test results under the same conditions.
The results from the MATLAB analysis indicated that the glottal area (area of gap between the folds) for the SLM was the most consistent of the three model types and that the glottal area was smaller, on average, than the EPI models at both duct lengths. However, qualitative analysis of the high-speed images revealed evidence that the SLM exhibits more inferior-superior displacement than the EPI model. A video comparison showed similar motion in both SLM and EPI models and signs of a slight alternating convergent-divergent profile, which is characteristic of human vocal folds.
Discussion:
During the first four months of this project, research was focused on increasing the reliability and throughput of the model making process. This refinement of the model making process was an unexpected, yet valuable, result of the project. Even still, a few of the models had slight imperfections and irregularities.
An advantage of the SLM is that the overall uncertainty in the quantitative results is less than the EPI model. This is significant because results of changes to the SLM in future iterations will be easier to determine and compare. Another advantage is that the SLM results were a closer representation of accepted values for human phonation and agree well with EPI model data gathered in previous studies.
The increased inferior-superior displacement of the SLM over the EPI models is a disadvantage of the SLM. The acrylic fiber embedded in the ligament layer of the EPI model is designed to attenuate this displacement and has made the EPI a better representation of human vocal folds than other self-oscillating synthetic vocal fold models. Future iterations of the SLM design are hoped to reduce this undesired displacement by developing other methods of introducing anisotropy into the ligament layer. One possible solution would be to embed loose glass or acrylic fibers oriented parallel to the medial edge.
Conclusion:
The SLM is easier to make than the EPI model because most of the problems with the model making process for the EPI model are associated with the ligament layer. Because the SLM was shown in this project to perform comparably to the EPI model, and more consistently than the EPI model, it has potential as an alternative model for future voice research.