Corey Wride and Dr. Parris Egbert, Computer Science
The original purpose of this project was to make the incredible resource of the Internet available to the visually impaired. The main contribution, however, has been a human-realistic text reader.
My first idea was to create a simple Internet browser that would download web pages in a text-only format and pass the information into one of the many pre-existing programs that read text. After creating this text-only browser, I had an idea of how to make my own text reader. Most all of the available programs use a computer generated voice to read text, but my idea suggested that a much clearer and realistic reader could be made by using recordings of a real human voice. The idea worked; and after several months of planning, programming, and recording of my voice, I had a text reading program that was easy to understand, and fun to use.
I began by recording common words and common parts of words. For example, to read the sentence “how are you doing today,” I created seven small sound files for the syllables: “how,” “are,” “you,” “do,” “ing,” “to,” and “day.” These words and sub-words are saved and combined as needed to read the above sentence. Fortuitously, the “to” sound can also be used for “too,” two,” and in some cases, “tu.” With a small amount of recorded sounds, a surprisingly large variety of sentences can be read. The more sounds recorded, the better quality the reader. I spent several days trying to computationally determine which words to record, but found it was easier to simply record new words as I found it necessary. Doing so revealed some interesting problems peculiar to English. One of the sounds I recorded was “ow,” to be used for “how,” “now,” and “shower.” That pronunciation was incorrect, however, for the words “show” or “know.” Overcoming these difficulties requires recording the common case sub-word as well as the many fullword exceptions. In every case, the longest recorded portions of each word are used. All of these sounds are numbered and stored in a database where they can be retrieved when needed.
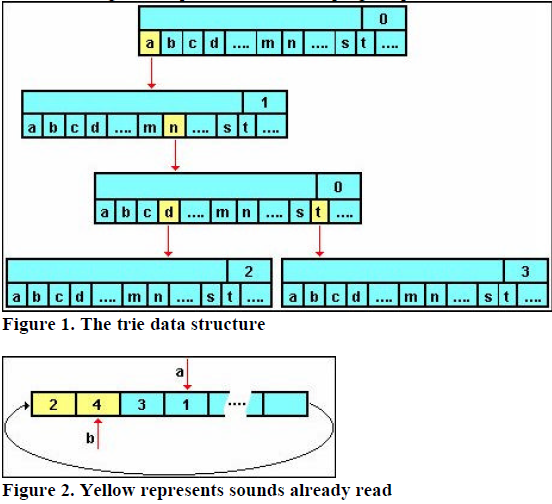
In order to quickly look up portions of words in such a large database of sounds, a trie data structure is used. The trie data structure consists of several nodes that are connected in a parent-children relationship. Each node consists of the index to a sound file, and twenty-six references to potential children (one for each letter of the alphabet). To build the structure, each word is added individually to an initial empty root node. Suppose the sounds “a,” “and,” and “ant” were to be added. The root node would initially have no references to children. To add the sound “a” a new node is created and the 1st (a = 1) child reference of the root node then refers to it. This new node contains a non-zero integer value which is an index to the sound “a” in the sound database. To add the additional sounds “and” and “ant” the 14th (n = 14) child reference of the second node needs to point to a new third node. Since we do not have a sound for “an” this new third node will have 0 for the index value. Finally, two more nodes are created with the appropriate indexes that stem from the 4th (d = 4) and 20th (t = 20) child references of the third node. The final structure can be seen in the Figure 1. Since looking up word indexes requires no searching or sorting, it is incredibly fast and helps make the distance between sounds unnoticeably small.
At about this point in my research I was blessed to meet Brook, a visually impaired computer user. She showed me how, after starting a Windows text reader called J.A.W.S., she could do word processing, check her email, and even surf the Internet. I was amazed to see how fast she moved from one program to another, without giving the computer-generated voice a chance to finish a sentence. Brook insisted that students with disabilities want to use the same software programs as everyone else, and wouldn’t be satisfied with a simple, text-only web browser. I felt if I could improve my text reader and get it to work in a commonly used program like Microsoft’s Internet Explorer, it might be preferred over the computer voice she had become accustomed to.
I began to restructure the way my text reader works. Instead of using a single program that would read words as they came, I created two sub-programs. Program “a” simply prepares the text to be read by the other program. For example, it decides what to do with capitalized letters and also translates special characters like “!” into user-defined words. This first program then looks up the sound indexes for each word in the trie structure and puts each index in a list that is used by the other program. This second program “b”, which runs simultaneously, simply marches along the list playing the appropriate sound for each index it encounters. In this way, the first program can run ahead and prepare the words for the entire paragraph, while the much slower sound player reads what is next on the list. If the user interrupts with different text to be read, the first program prepares it, adds it to the list, and tells the second program to skip ahead to the new sound indexes. If either of the program gets to the end of the list it will wrap around to the beginning and continue seamlessly. If the second sub-program runs out of sound indexes to play it will simply go to sleep until there are some, freeing the computer to do work for other running programs. In Figure 2 the sound indexes in yellow represents sounds that have already been read.
Once the word reader became robust and reliable, I was faced with the task of making it work with a common web browser. The main engine of Internet Explorer (a COM component) is separate from the rest of the program, which made it easy to create a web browser based upon it. I ended up using a sample project created at Microsoft by David S. Miller called MFCIE that was set up with the same look, feel, and engine of Internet Explorer 4.0. After hacking into it a bit I was able to add my own buttons and text Windows. The final steps were to (using Windows hooks) intercept text entered from the keyboard as well as text displayed to the screen from the program so they could be read. The later proved much more complicated and has left me plenty of work to make the program really usable for the visually impaired.
Future work, therefore, may be to determine exactly what text on the screen should be read, and how to intercept it. The current implementation also restricts the keyboard and text interceptions to my web browser only. I was delighted to discover that it is trivial to make those interceptions work systemwide. Doing so would eliminate the need for the actual web browser program, and would allow this realistic text reader to be used in any Windows program.
Before running the sample WebReader.exe program please read the ReadMe.txt file.