
Roger Scott Twede, Department of Electrical and Computer Engineering
Introduction
While attempts to create speech recognition systems have surfaced over several decades, obstacles limit the capabilities and performance of current systems. Nonetheless, the promise of incredible benefits and myriads of applications drive the technical world to continue the attempts.
Applications of Speech Recognition
While some reject computer speech recognition as only a novelty, many useful applications exist Verbal communication provides a more natural means of computer input than a keyboard or mouse. Not only could costly computer training be reduced, but the computer’s ability to take dictation allows ideas to be captured easily and instantly for reproduction on paper or transmittal by e-mail around the world. Handsfree operation of a computer would reduce repetitive stress injuries such as Carpel Tunnel Syndrome. Those with physical handicaps could obtain increased autonomy and control of their surroundings while having easy access to information. Without interrupting a complex surgical procedure in progress, a surgeon could verbally consult a computer for the medical records of a patient. Such are only a few of the possibilities.
Obstacles to Speech Recognition
The following are some of speech’s inherent properties that make recognition difficult:
- Continuous speech tends to blur words together making them
difficult to isolate.
- Variations between speakers such as accents, gender and pronunciations
complicate recognition.
- Large vocabularies contain many similar sounding words with
little to differentiate them.
- Background noise and room acoustics alter the pronounced
sounds.
System Design
Because the human brain successfully interprets speech, I chose to investigate neural networks as a means of speech recognition. Neural networks attempt to learn by making associations which emulate the neural connections in a human brain. Therefore, the networks have at least a partial ability, to generalize and pick out common characteristics from a set of varying samples. On the other hand, typical recognition systems use a different approach. They seek to compare each spoken word to templates in a “dictionary”. The system then chooses the closest matching template as the word that was spoken. The template approach was not used in this study because the aforementioned obstacles make it almost impossible to choose a single template that will still match all the numerous variations of a word.
Having chosen the neural network approach, the next step consisted of transforming the verbal communication into a form that could be teamed by the network. A microphone converted the sound waves into electrical waves which were then sampled by the computer at 22255 Hz. The digital signal was then downsampled 2:1 to reduce the number of samples. A single word required 3,500 to 10,000 samples to be represented in digitized form.
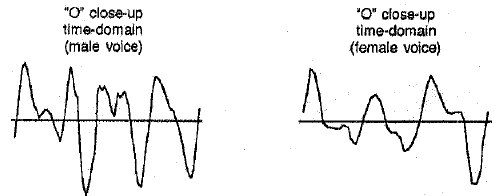
A successful training session with the neural network required two criteria to be met. First, a small amount of input data needed to be extracted which accurately represented the spoken word. Second, the extracted data needed to contain recognizable patterns for the network- to identify and learn. The digitized waveform failed in both respects. The appearance and shape of the waveforms lacked similarity between different speakers, even when the same sound was pronounced.
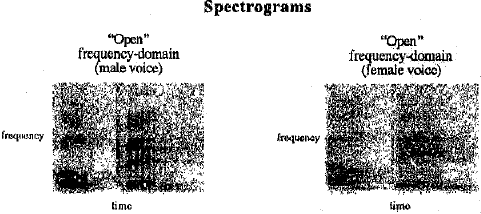
Male and female pronunciations of the same words were analyzed to search for ldentlflable patterns. The raw data, or sound amplitude plotted as a function of time, produced waveforms which differed immensely between male and female voices. However, when transformed from the time-do- 111<1in to the frequency-domain, conm1on patterns emerged. In other words, by plotting a word's frequency distribution as a function of time, otherwise known as a spectrogram, similar words produced similar patterns. Therefore, the next manipulation involved dividing the digitized waveform into 65 evenly-spaced windows of 128 samples each and then taking the Fourier Transform of each window. The process resulted in the spectrogram of the word. The drawback to this representation is that the number of integers needed to represent the spectrogram still exceeded 4,000. In order to reduce the amount of data, the frequency which contained the most power in each of the 65 windows was extracted, leaving only 65 integer values to represent the word. In the spectrograms this process corresponds to extracting the darkest point in each of the 65 columns of varying gray.
Neural Network Training
A search was conducted for a neural network capable of training itself on the data extracted from the spectrograms. A neural network developed by the University of Nevada Center for Biomedical Modeling Research, obtained via the Internet, was chosen for use in the system. The network was configured in three layers. Layer one contained 65 Input nodes, layer two contained 32 hidden nodes, and layer three contained 10 output nodes. Each node acted as a single brain cell with connections of varying strengths that extended to every other node In the next layer. Therefore, each Input node could communicate data to every hidden layer node, and each hidden layer node to every output node. When any node was stimulated an impulse would be passed along its connections to neighboring nodes. The strength of the impulse along each connection was dependent upon the strength of the connection. The impulses simulate the brain impulses that travel along a nerve cell’s axon and through the dendrites, finally stimulating another nerve cell. Each of the ten output nodes was associated with a single vocabulary word. The output node which received the most stimulus by way of Impulses determined which of the ten words was spoken.
Neural network training consisted of achieving the correct connection strengths for each of the 2,400 connections. Initially all of the connection strengths were chosen at random. The data of a sample word was fed into the network on the 65 input nodes and the impulses were allowed to propagate until the dominant output node was evident. Often, the correct output node was not stimulated so connection strengths were adjusted to cause the correct output node to fire. Fifteen examples of each of the ten words were repeatedly fed into the network and connection strengths adjusted accordingly. Each sample was input 1,375 times before 100% accuracy on the training set was achieved.
System Performance
After training was completed, new recordings of the ten words were made and fed Into the network. On the newly spoken samples the network identified all of the words correctly. The network was more than 80% sure on eight of the words. However, the words “empty” and “object” were only predicted with 52% and 61% surety in the test run. A full project specification and report have been submitted to the BYU electrical engineering department giving further details of this research.
Future Possibilities
The neural network approach to speech recognition merits continuing investigation. Because neural networks are still in their infancy, many advances still lie ahead. In order for computers to achieve humanlike speech recognition on large vocabularies, the neural networks need to be expanded. Because human speech is full of imprecise sounds, the human brain must fill in the gaps from the context. Multiple networks which analyze speech on phoneme, syntactical, and contextual levels should be employed. Feedback from each level of analysis could then be used to identify the spoken words. It appears that sound wave analysis alone is inadequate to accurately identify complex language. Therefore, until context and syntax are incorporated into the analysis, computer capabilities will remain below human levels and recognition errors will be prevalent. As the capacity and speed of computers increases, complex analysis will become more and more reasonable, and the day will arrive when our computers will truly listen when we speak.