
Landon Sego and Drs. Howard B. Christensen, Statistics; Stephen J. Bahr, Sociology
Objective
To investigate and quantitatively document the differences between analyzing survey sample data with traditional statistical software (SAS) and with statistical software designed for the analysis of survey samples (SUDAAN).
Background
Most standard statistical software packages perform calculations based on the ideal assumption that the data come from a simple random sample. However, it is nearly impossible to achieve a pure simple random sample when conducting a survey due to prohibitive costs and other logistics in gathering data. Because most large scale survey samples involve stratification and/or multistage sampling, the proper analysis of survey sample data necessitates taking into account the nature of the sampling technique. Survey sample software (such as SUDAAN, OSIRIS, or PCCARP) is designed specifically to calculate statistics based on the design of the survey sample. In the past, many scientists and researchers have used standard statistical software packages (such as SAS, SPSS, or BMDP) to analyze survey sample data despite a growing awareness that these standard software tools are not suited to the task.
At its most basic level, there are two primary tasks in the analysis of survey sample data. The first is to obtain the most accurate point estimator possible. A point estimator is a statistic, such as an average or a percentage, calculated from a sample that can be used to make inferences about a population. Using sampling weights in the analysis produces point estimators that are unbiased or nearly so. When the same sampling weights are used, both SAS and SUDAAN produce the same values for point estimators.
The second task is to correctly estimate the variance. Since SAS and SUDAAN use different algorithms to calculate the variance, the results differ between the two software packages. SUDAAN acknowledges the sample design when computing the variance, while SAS calculates the variance based on the assumption that the data come from a simple random sample. As a result, in the analysis of sample survey data, SAS variance estimates tend to be smaller than SUDAAN variance estimates. Because SUDAAN is specifically designed for the analysis of survey sample data, the variance estimates generated by SUDAAN are accepted as being more accurate than those produced by SAS.
The lower variance estimates produced by SAS are of critical concern because they can lead a researcher to draw incorrect conclusions. Smaller variances produce smaller confidence intervals which can give the researcher a false sense of security about the accuracy of a point estimator. Underestimating the variance can also lead to inaccurate conclusions in a statistical test of hypothesis. The lower p-values that result from smaller variances lead researchers to reject the 272 null hypothesis more often than they should. This means that researchers may incorrectly conclude that there exist dependencies or differences in the data when there is insufficient evidence to draw that conclusion.
Data Source
In order to compare the differences between SAS and SUDAAN, I analyzed a large survey that Dr. Stephen J. Bahr of the BYU Department of Sociology conducted in conjunction with the Utah State Division of Substance Abuse. This stratified, one-stage cluster sample survey was designed to determine drug use and factors related to drug use among secondary education students in Utah. Between March 1997 and June 1997, the survey was administered to 10,490 students in 533 Utah classrooms around the state.
Findings
In comparing the differences between SAS and SUDAAN with respect to the Utah Drug Survey, I found that the results of my comparison concur with those reported in previous studies (see References). As expected, weighted estimators were the same for SAS and SUDAAN. However, the variance estimates between SAS and SUDAAN differ considerably. Table 1 compares three methods that could be used when estimating the use of cigarettes within the past thirty days among Utah secondary education students.
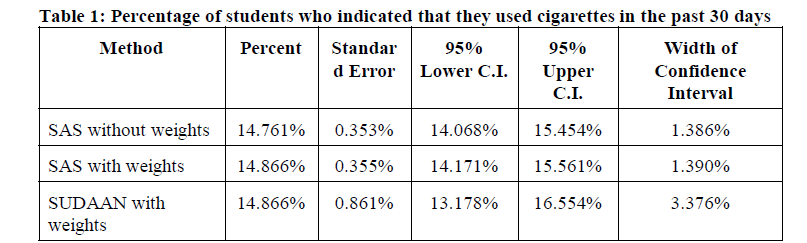
* This SUDAAN estimate is one of more than 1,100 estimates I provided to Dr. Bahr for inclusion into the report he submitted to the Utah State Division of Substance Abuse.
Note that when weights were used, SAS produced the same estimate of the percentage of cigarette use as did SUDAAN. However, the primary concern remains the estimate of the variance. The standard error calculated by SUDAAN is more than double the standard error calculated by SAS, resulting in a SUDAAN confidence interval that is more than three times the width of the SAS confidence interval. The variance estimates produced by SAS would indicate that the estimated percentage of cigarette use has a margin of error of ±0.69%, when, in fact, the margin of error for the percentage is ±1.69%.
Lower variance estimates also affect statistical tests of hypothesis. If I were interested in testing whether there was a significant difference in the level of smoking between the Millard and Washington School Districts, and I used SAS to calculate the variance estimates, the resultant p-value of 0.009 would lead me to conclude that the percentage of students who indicated that they used cigarettes in the past thirty days is higher in Millard (18.74%) than it is in Washington (12.11%). However, using SUDAAN to calculate the variance, the p-value is 0.153. This means that at the 0.05 level of significance there is insufficient evidence to conclude that there exists a statistically significant difference between the smoking rates of the two districts.
Conclusion
In order to correctly analyze survey sample data, the nature of the sampling must be considered. Using sampling weights and software specifically designed for the analysis of survey sample data (such as SUDAAN) will ensure the accuracy of point estimators and variance estimates. This accuracy validates the inferences and conclusions made about statistical populations.
References
- Brogan, Donna J. Ph.D. 1997. “Pitfalls of Using Standard Statistical Software Packages For Sample Survey Data.” This article will appear as a chapter in Encyclopedia of Biostatistics, edited by Peter Armitage and Theodore Colton, to be published by John Wiley in summer 1998, as six volumes. The article will be in a subsection titled “Design of Experiments and Sample Surveys,” edited by Paul Levy.
- Eltinge, J.L., V.L. Parsons, D.S. Jang. 1997. “Differences Between Complex-Design-Based and IID-Based Analyses of Survey Data: Examples from Phase I of NHANES III.” Stats. No. 19: pp. 3-9.