Nancy Owens and Professor Todd Peterson, Computer Science
Robotic controllers often fail to perform well when transferred from a simulated environment to a real-world situation. Such failures are caused by discrepancies between a simulator and the real-world system which it is intended to model. Traditional approaches to this problem attempt to reduce the number and severity of simulator/environment discrepancies by using calibration, by designing more accurate simulations, or by controlling the specifications of the real-world environment. These approaches, although often effective, are limited in that they require the designer to successfully anticipate the types of discrepancies the controller is likely to encounter.
We have chosen to explore a different approach. Rather than attempting to reduce simulator/environment discrepancies, we overcome them by using a Q-learning controller which adapts to unexpected changes in its environment. Q-learning is a type of reinforcement learning which utilizes a designer-defined reward structure to predict the utility of performing a given action in a given state. In Q-learning, an expected discounted reward, called a Q-value, is maintained for each possible state-action pair. These Q-values are then updated to reflect the positive and negative rewards received by the controller during its exploration of the environment.
The traditional Q-learning approach to a change of environments is to initialize the Q-values for the new environment with the final Q-values from the old environment. This is called Direct Transfer of Q-values. Direct transfer of Q-values alone is capable of overcoming simulator/environment discrepancies, but the time required to unlearn incorrect portions of the policy makes this method infeasible for many real-world applications. We therefore chose to study three supplementary algorithms in order to allow faster adaptation to the new environment. These algorithms are called Memory-guided Exploration, Soft Transfer of Q-values, and KNN Q-value Prediction.
In Memory-guided Exploration the Q-values from the previous environment are used to bias the controller’s behavior as it learns appropriate Q-values for the new environment. The controller effectively relies on past experience to guide its exploration towards more desirable regions of the state space. In Soft-Transfer of Q-values the final Q-values from the previous environment are maintained, but the distinctions between Q-values for specific actions are blurred. In this way, critical prior information is preserved, but the unlearning process is simplified. KNN Q-value Prediction is a method which predicts the likeliest Q-value of previously unvisited states, based on the Q-values of nearby states. This allows the agent to behave reasonably in new and unexpected situations.
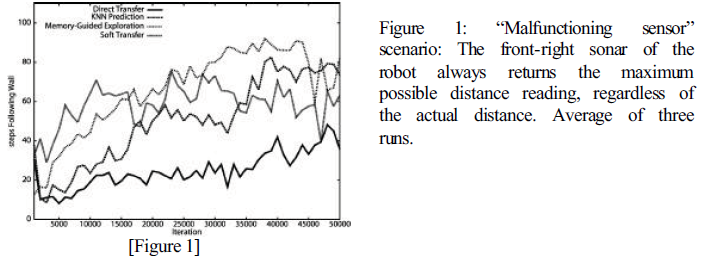
We used a Nomad Simulator to compare the effectiveness of these algorithms in several artificial cases of simulator/environment discrepancies. The Q-learning controller was initially trained on a simple wall-following task in a rectangular room. The controller was then required to perform the same task in the face of various environment discrepancies, such as sensor malfunctions or the addition of a wall, which were artificially introduced into the simulation. The performance criteria was to maximize the percentage of time spent following the wall. In general, all of the supplementary algorithms performed better than Direct Transfer of Q-values. An example result is shown in Figure 1.
These methods were then applied to a case of true simulator/environment transfer in which a simulator-trained controller was transferred to an actual Nomad Scout robot. The controller was initially trained to perform a wall-avoidance task in a rectangular hallway. The controller was then transferred to a real hallway with dimensions equivalent to those of the simulated map, and was required to perform the same wall-avoidance task. The performance criteria was to minimize the number of collisions with walls.
In the initial run, all algorithms appeared to be functioning with approximately the same efficiency. This probably occurred because the simulated and real environments were too similar—the discrepancies were not severe enough to make Direct Transfer of Q-values inefficient. To test this theory, we made the transfer more difficult by introducing an artificial sensor malfunction identical to that which produced Figure 1. The results reveal that, when the severity of the discrepancy was increased in this manner, Soft Transfer adapted more than twice as quickly as the other algorithms.
In conclusion, this research has demonstrated that a Q-learning controller applying appropriate supplementary learning algorithms can successfully overcome some types of simulator/environment discrepancies in a reasonable amount of time. The advantage of this approach is that the controller is capable of overcoming simulator/environment discrepancies which were not anticipated by the designer, and therefore could not be prepared for in the simulation phase. A more detailed account of this research will be available in the Proceedings of the 2001 IEEE Systems, Man, and Cybernetics Conference, which will be held in Tucson, Arizona this October.