
Tanner Thompson and Dr. Ryan Jensen, Department of Geography
Introduction
Kelp forests provide food and shelter for many organisms, and they are an important part of coastal ecosystems throughout the world. Along the Pacific coast of the United States, kelp forests are made up of one of two species of kelp: bull kelp (Nereocystis Luetkana) and giant kelp (Macrocystis Pyrifera). While similar, these two species are physiologically and structurally different.
The kelp forests along the California coast have diminished drastically in extent in the last several years. Ocean scientists studying the changing kelp forest ecosystem need accurate and timely maps, but due to limitations in past and current mapping methods, kelp forests have not been mapped at the species level. In other words, current maps can show where the kelp forests, but cannot distinguish forests composed of giant kelp from forests composed of bull kelp. Of course, due to the structural differences in the two species, human surveyors in the water or in low-flying planes are able to tell them apart easily. This method, however, is hard to scale, and would be prohibitively time-consuming.
Remote sensing – the observation of the earth through an imaging sensor on a plane or satellite – is most commonly used for this task due to its scalability. Unfortunately, common satellite imagery, such as Landsat, does not provide enough information to distinguish between the reflectance spectra of the two species. Hyperspectral imagery, however, provides several times as much information per unit area. Hyperspectral imagery analysis has been applied to similar problems in tree species classification with very encouraging results. This study aims to apply similar methods to kelp species classification.
Methods
AVIRIS (Airborne Visual/Infrared Imaging Spectrometer) is NASA’s primary hyperspectral imaging system. AVIRIS provides calibrated upwelling spectral radiance measurements in 224 spectral bands (Landsat, for comparison, provides eight bands). In this study, data were acquired from NASA’s publicly available AVIRIS data portal. Eight images of the California coast were used from AVIRIS flights on board NASA’s ER-2 between 2013 and 2016.
The images were processed and analyzed using Python. The Spectral Python package was used to read in and visualize the images, numpy was used to manipulate the image data, and scikit-learn was used to apply the machine learning models. All analysis was done inside a Jupyter notebook, which is available on GitHub.
In order to apply supervised machine learning methods, a training set was needed. Survey data from the Reef Check Foundation, a volunteer coastal surveying organization, showed that all canopyforming kelp recorded in the last several years north of San Francisco was bull kelp, and all south of Point Conception in southern California was giant kelp. So, these cutoffs were selected as thresholds for gathering training data.
Next, the pixels in the imagery representing kelp needed to be positively identified. Criteria selection for kelp identification was done by manual choice and tuning of heuristics, such as NDVI.
Once the kelp pixels were identified, the training data were separated out according to the latitude criteria given above, and a test set was randomly selected representing 25% of the total training data. Nine machine learning methods were then tested, some with multiple sets of parameters. For each method (and set of parameters), the given model was trained on the leftover 75% of the data and then asked to classify the remaining 25%. The accuracy of the classification was recorded.

Results and Discussions
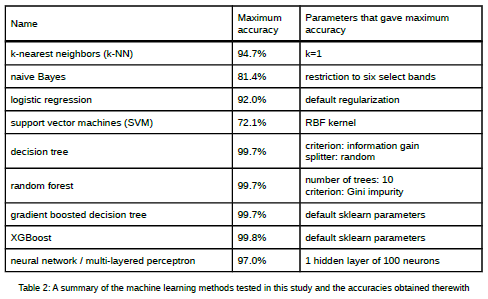
As can be seen from the table, tree-based methods (decision trees, random forests, gradient boosted trees, and XGBoost) were the clear winners. This is likely due to how these methods treat highdimensional data – each dimension is only considered as it is needed, meaning dimensions that have high correlations can be ignored. In contrast, methods like naive Bayes or logistic regression consider every dimension of every piece of training data when training and classifying.
Conclusion
This study has demonstrated that AVIRIS hyperspectral data can be used in conjunction with machine learning methods to accurately map kelp off the pacific coast of the United States. Specifically, the study provides the following conclusions: 1) Kelp can be mapped at the species level with AVIRIS aerial hyperspectral data, and 2) Decision tree and decision tree based methods outperformed other kinds of machine learning algorithms because they are not typically influenced by higher-order datasets.
Future studies could focus on the ability of different types of hyperspectral data (e.g., CASI or AISA+, etc.) to accurately map kelp using the same or similar techniques. Further, different study areas and species of kelp could also be studied to determine the transferability of this study’s methods and results to coastal areas throughout the world.