
Anna McConner-Hughes and Dr.Wendy Baker-Smemoe, Linguistics Department
Introduction
The purpose of this study is to examine the learning of English consonants by native Armenian speakers. In particular, we examined how the native Armenian speakers perceive and produce English voiced and voiceless ‘th’ sounds (as in the words thy and thigh (/ð/ and /θ/ in IPA)). These sounds are difficult for learners to acquire, in part because they are often confused with each other. The results of this study will help us better understand the relationship between first and second language sound systems and will hopefully lead to training materials to help native Armenian speakers better learn English.
One of the main questions in L2 speech perception and production research is how the native (L1) and second (L2) sound systems influence each other. Much of the work that has been done in L2 acquisition has involved examining learners acquiring L2s that have a sound system quite similar to their L1, even if the language families differ. It is through the study of uncommon languages (those that differ greatly from the learner’s first language) that a greater understanding of L2 acquisition can occur. Thus, this study is unique in that it tests a unique language learning group (Armenian speakers learning English). In addition, this research will also be used to create materials to help Armenians to better learn English.
Methodology
Participants were native Armenian speakers learning English. First, participants filled out a language background questionnaire. Second, participants were recorded saying a list of words that contained English voiced and voiceless ‘th’ sounds (as in the words thy and thigh (/ð/ and /θ/ in IPA)). Lastly, participants performed identification and cross-language identification tasks. For the first task they heard consonants in English and Armenian and were asked to identify them. For the second task, they heard an English consonant and were asked to identify it with an Armenian consonant (whichever one they think sounds the most similar to the English consonant). For example, they heard the English consonant in the word “thy” and were asked if it sounds more like Armenian /t/, /d/, /t’/ or another Armenian sound. These types of tasks are very common in L2 pronunciation acquisition research. I travelled to Armenia this summer and collected data from adults (18+) who are native Armenians learning English. We also tested participants who now live in Utah (i.e., immigrants from Armenia). We acoustically analyzed the speakers’ productions using a speech software program (Praat), and compared native speakers’ productions with those of non-native learners. We determined how accurately the participants perceive the consonants by comparing native speakers to non-native speakers. Production are analyzed with acoustic analyses and native speaker judgments.
Results
Our results answered our three research questions and are explained below:
1.What is the perceptual relationship between English interdental fricatives (as in the words thy and thigh) and Armenian alveolars (/t/, /d/ and /t’/)?
Native Armenian speakers perceive English interdental fricatives as sounding most like Armenian /f/ and /v/, not like English /t/ and /d/. This was true in all phonetic environments, but especially true in final word position (see table below)
2. How does this relationship affect the perception and production of these sounds by Native Armenian speakers of English?
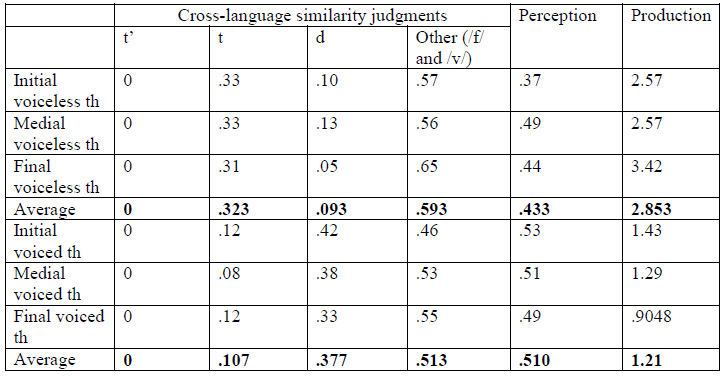
Native Armenian speakers were more accurate in their production of voiceless /θ/ than voiced /ð/ (F(1,5) = 8.46, p = .006; eta = .190), but there was no difference in accuracy across phonetic environment (F(2,5) = .065, p = .937, eta = .004) for either voiced or voiceless interdental consonants (F(1,2)=1.21, p = .309, eta = .063).
By contrast, there was no significant difference in the perception of voiceless /θ/ and voiced /ð/ by the native Armenian speakers (F(1,19) = .422, p = .657, eta = .007), in any of the phonetic environments (F(2,19) = 1.27, p = .261, eta = .011) nor an environment by voicedness interaction (F(1,2)=.851, p = .430, eta = .015).
3. What do these findings tell us about the relationship between L1 and L2 sounds?
Native Armenian speakers were more likely to identify voiceless interdentals with a single sound in Armenian than they were to identify voiced interdentals with a single sound. In addition, they were also more accurate in producing voiceless interdentals than voiced interdentals. This suggests that this cross-language similarity may have helped them to produce the voiceless interdentals more accurately. However, this cross-language similarity did not seem to affect the perception of the sounds.